

Jupyter Notebook で Python を使う2023/07/17(月)
実験データをグラフ化したり、関数でフィッティングしたりするソフトウェアとして、以前に R を紹介しました。R は高機能で実績もあるのでよいのですが、ちょっとクセが強くて、ハードルが高いことは否めません。結局自分が常用していない、というのが現実です(苦笑)。
そこで、最近使うことが増えてきた Python でやってみることにしました。Python だってハードルは低くはないのですが、R とは違って汎用のプログラミング言語なので、一度覚えておけば使い道が多いという利点があります。
Python のインストールについては、以前「電気化学のシミュレーション:Pythonを使ってみる」という記事で紹介しました。今回は、これに加えて、対話的に Python を実行できる Jupyter Notebook という環境を使ってみようと思います。
注意1:Python をインストールする前に、Windows のログイン名を確認しておいてください。ここに日本語の文字が入っていたり、半角のスペースなどの記号が入っていたりすると、Jupyter Notebook がうまく実行できないことがあります。半角英数字とアンダーバーだけのログイン名を持つユーザーを新しく作ってください。(やり方は「Windows 新規ユーザー作成」などで検索してください。)
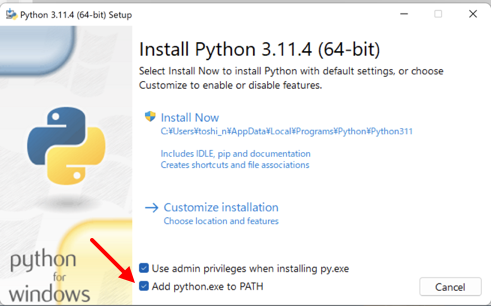
注意2:Python を Microsoft Store 経由でインストールすると、Jupyter Notebook がうまく実行できないことがあります。Python 公式サイトからインストーラをダウンロードして、手動でインストールしてください。このとき、"Add python.exe to PATH" のチェックを入れておいてください。Jupyter Notebook を実行するときには、この設定が必要になります。
Python がインストールできたら、Windows PowerShell を開いて、次の行を実行してください。この通りにタイプして、最後にEnterキー(Returnキー)を押します。
python -m pip install jupyter
大量のメッセージが表示して、"Successfully Installed …" と表示されて終わればOKです。何かエラーが発生した時は、タイプミスがないかどうかをまず確認してください。
次に、数値計算を行うためによく使うライブラリをインストールしておきます。
python -m pip install numpy scipy matplotlib pandas
numpy は数値計算(特に行列の演算)、scipy は科学技術計算一般、matplotlibはデータのグラフ化、pandas はデータ入出力に使うパッケージです。
「ドキュメント」フォルダの中に「Python」というフォルダを作っておきます。PowerShell 上で次のようにタイプすると、Python フォルダの中で Jupyter Notebook が立ち上がります。
cd Documents\Python
jupyter notebook
最初の画面は次のようなものです。今は Python フォルダの中は空なので、何も表示されていませんが、ファイルやフォルダがあれば、それが表示されます。
データを読み込んでグラフ化してみましょう。下のようなテキストデータが data1.csv というファイルに入っているとしましょう。csv(コンマ区切り値)ファイルは、メモ帳などで手打ちでも作れるし、Excel で CSV 形式を指定して保存しても作れます。
0.0, 0.00
0.1, 0.18
0.2, 0.47
0.3, 1.03
0.4, 1.72
0.5, 2.69
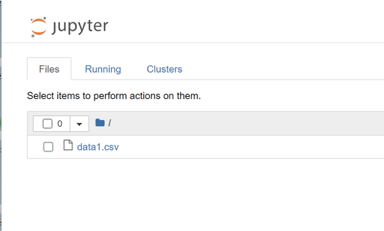
このファイルを、ドキュメント\Python フォルダの中に入れておきます。Jupyter Notebook の画面でも見えています。
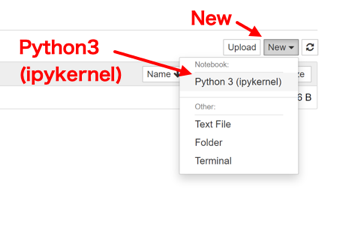
それでは、Python プログラムを書いてみます。最初に、右上の「New」ボタンから「Python 3 (ipykernel)」を選びます。
ブラウザで新しいタブが開き、「In [ ]」という表示が出ます。ここにプログラムを書きます。
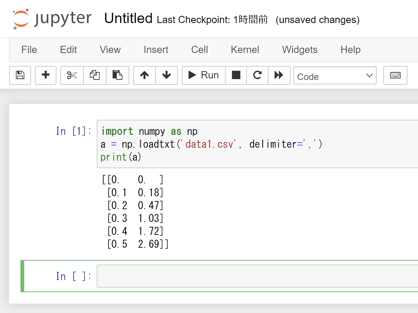
以下の3行をタイプしてみます。data1.csvを読み込んで二次元の配列(行列)データとして、変数 a に納め、それを表示するプログラムです。numpy の loadtxt という関数を使っています。
import numpy as np
a = np.loadtxt('data1.csv', delimiter=',')
print(a)
Shift+ENTERでプログラムを実行できます。このようになります。
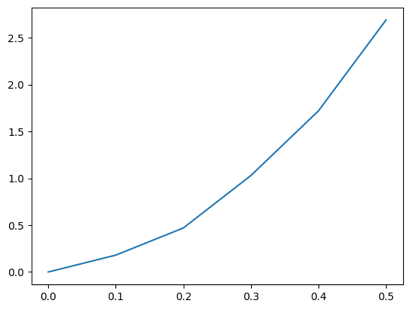
データをグラフ表示してみます。先ほどのプログラムに書き足して、以下のようにします。matplotlib.pyplot の figure, add_subplot, plot という関数を使っています。(「matplotlib.pyplot の add_subplot という関数」という説明は不正確ですが、正確を期すと話が長くなります。詳細はご自身でお調べください。)
import numpy as np
import matplotlib.pyplot as plt # 追加
a = np.loadtxt('data1.csv', delimiter=',')
print(a)
fig = plt.figure() # 追加
ax = fig.add_subplot() # 追加
ax.plot(a[:,0], a[:,1]) # 追加
こんなグラフが表示されます。
このコードでは、a[:,0] という表記が異様な印象を与えます。これについて解説しておきましょう。a という二次元配列の数値は、下のように並んでいます。(添え字が0から始まることに注意)
a[0,0] | a[0,1] |
a[1,0] | a[1,1] |
a[2,0] | a[2,1] |
a[3,0] | a[3,1] |
a[4,0] | a[4,1] |
a[5,0] | a[5,1] |
このグラフでX軸の値になるのは、a[0,0]〜a[5,0] の6個の数値です。これを、Pythonでは a[0:6,0] と書きます。0:6 は「0以上6未満」という範囲を表します。範囲の下限・上限の値は省略できます。下限・上限を両方省略すると、範囲の表記は : だけになります。これを使うと、a[:,0]は「第0列の全部の値」を表すことになります。Y軸の値は、同じように考えて、a[:,1]となります。
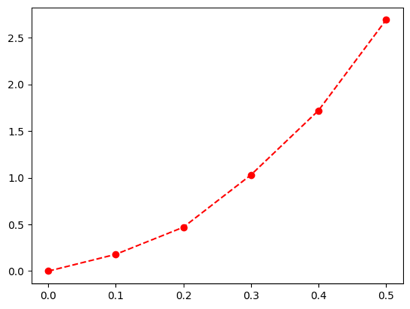
グラフの表示は、plot にオプションを指定することで変更できます。たとえば、丸印のマーカー・点線・赤色で書くには、ax.plot(a[:,0], a[:,1], "o--r") とすると、下のようになります。
長くなったので、今回はここでいったん終了とします。関数を使ったフィッティングについては、後日書きます。