

R Studio を使ってグラフを描く2019/01/18(金)
化学の研究を進めていると、実験データをグラフ化することがしばしば必要になります。前任地ではずっと Igor Pro を使っていました。今でも自分で論文を書くときには使っています。しかし Igor Pro は、けっこう値の張るソフトウェアです。学生用のパソコンの数だけライセンスを揃えるのは、経済的な負担がかなり大きいのです。また、グラフソフトといえば Excel、と思っている人も多いのですが、Excel はあくまでも「表計算」ソフトです。研究レベルの科学技術計算に使うべきものではない、と私は考えています。
何とかフリーのソフトウェアでできないものかな、と思い、R を試してみることにしました。R は、統計計算に特化したフリーソフトウェアです。専用のプログラミング言語と、結果を表示するためのグラフィック環境がセットになっています。計算機の専門家向けのソフトウェアなので、「誰でも簡単に」使えるものではありません。しかし、統計計算用のフリーソフトウェアとして 20 年以上の実績があって、世界中にたくさんのユーザーがいますので、使い方を学んでおいて損はないでしょう。少なくとも「グラフソフトは Excel しか知りません」というよりは良いかなと思います。
手元のパソコンで使えるようにします。「R」本体と、「R Studio」をインストールします。
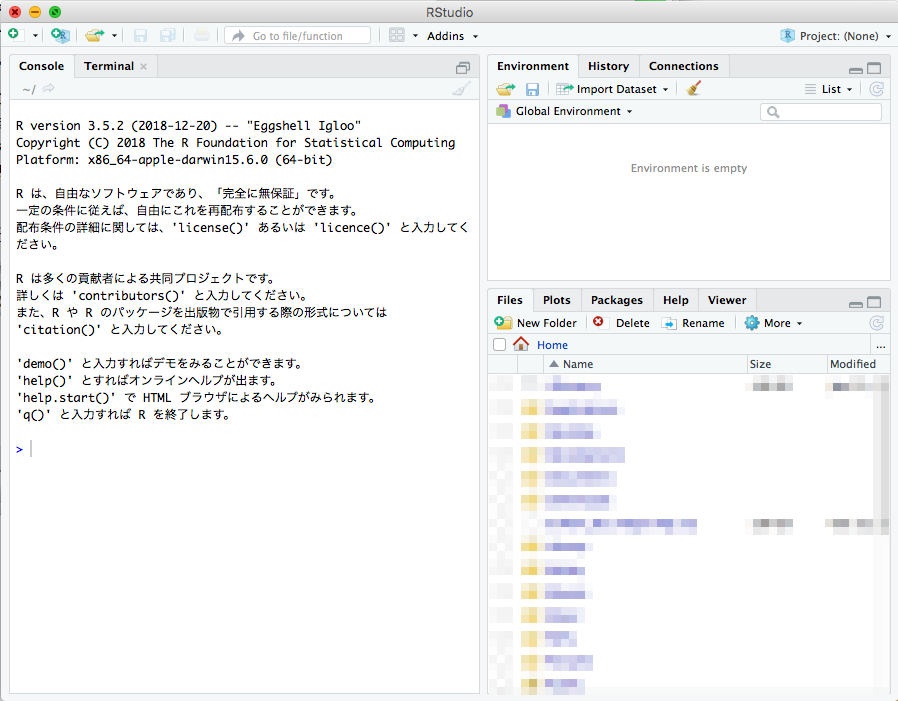
R Studio を立ち上げると、こんな画面になります。
私の研究分野でこういうソフトウェアを使うときは、ほぼ 100%、「2つの数値の対を並べたもの」をグラフ化したり、それをある曲線で近似したりする用途です。データは Excel に入っていることが多いでしょう。下のようなデータがあるとしましょう。「時間、A の量」という数値の対を並べたものです。
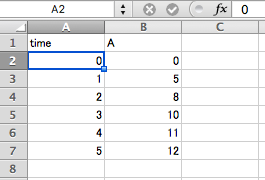
1行目がタイトルで、2行目以降に数値データが入っています。このような Excel データは、R で直接読み込むことができます。
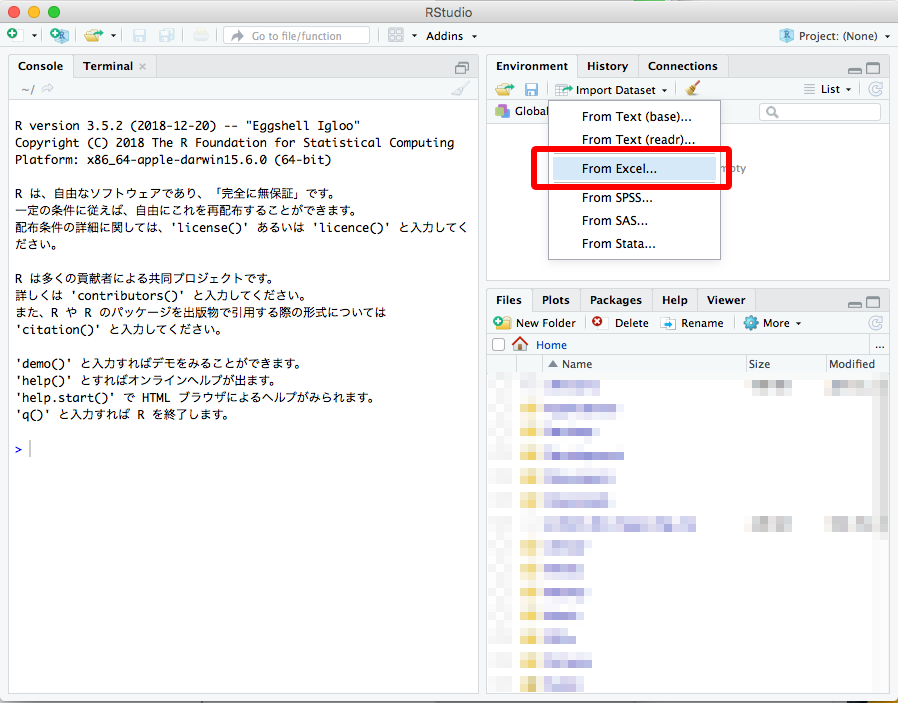
"Import Dataset" から "From Excel..." を選ぶ。
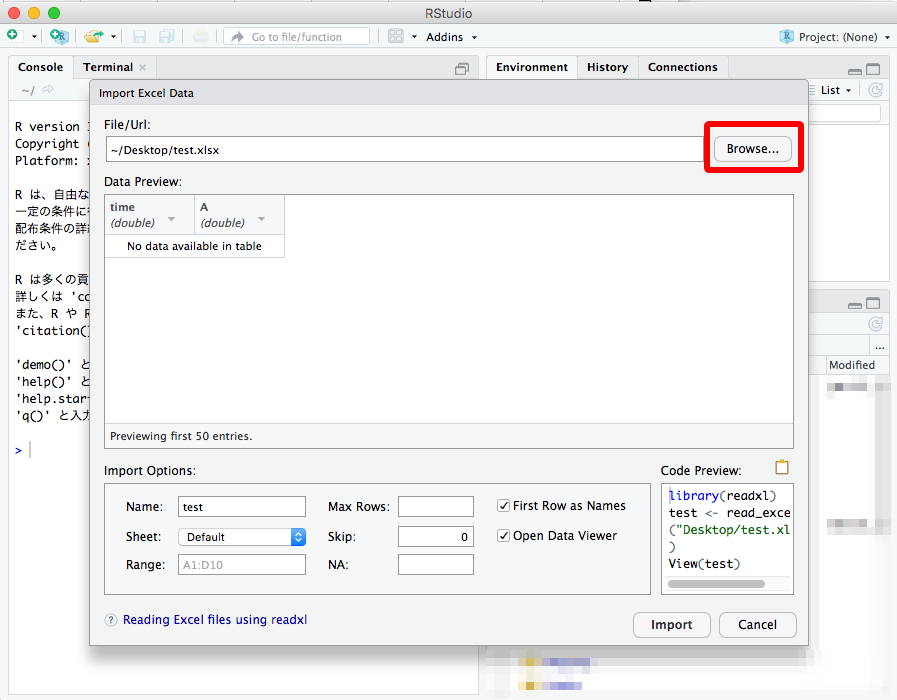
"Browse..." でファイルを選ぶ。
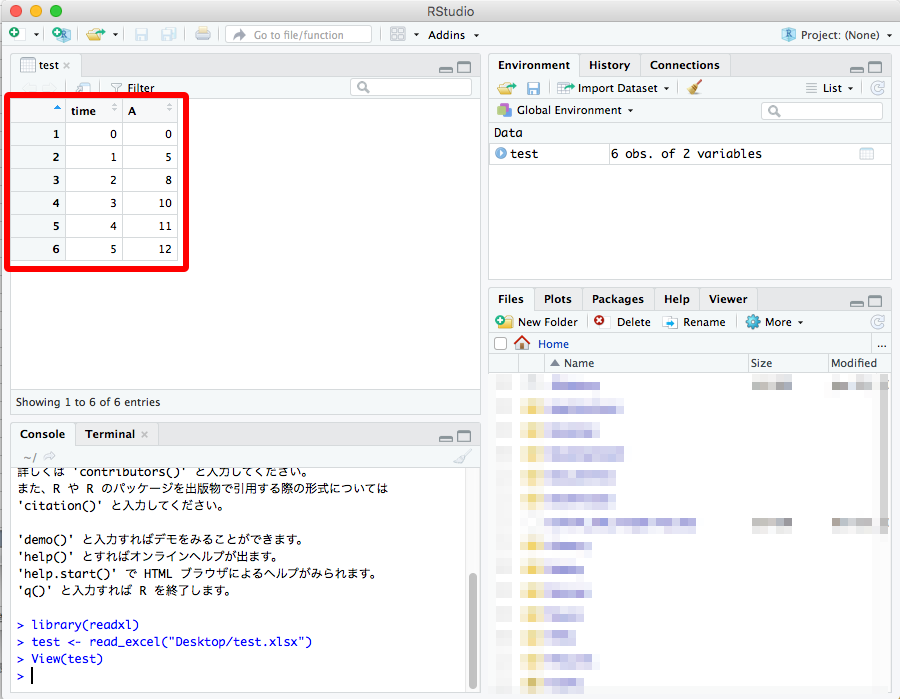
データが表示される。
グラフを描いてみます。左下の "Console" のところに、コマンドを打ち込むと、右下のプロットエリアにグラフが描かれます。
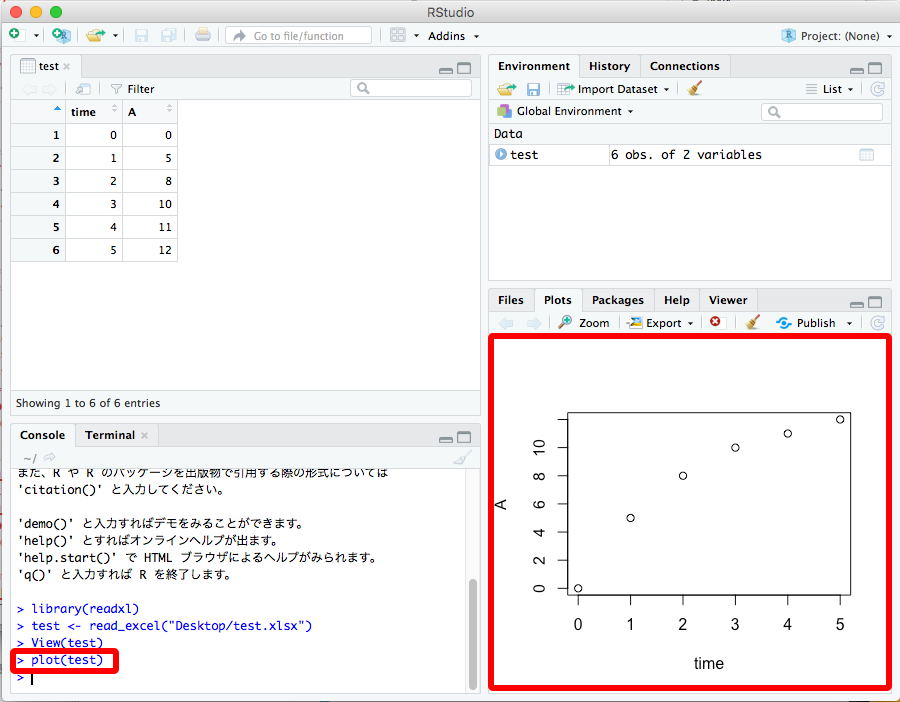
このデータを、適当なモデルでフィッティングしてみましょう。直線とか二次関数とかだと、「そんなの Excel のほうが簡単だよ」とか言われてしまいそうなので、もう少し凝ったモデルでやってみます。このデータを「一次の可逆反応が平衡に達する挙動である」と考えて、y = a (1 - exp(-bx)) という式にあてはめます。
左下の "Console" で、次のコマンドを打ち込みます。
> fit = nls(A ~ a*(1-exp(-b*time)), test, start=c(a=12,b=1))
nls は、非線形最小二乗法 (nonlinear least squares) を実行するコマンド。A ~ a*(1-exp(-b*time)) は、A と time の間の関係式。A, time というのは、テストデータの中のデータの名前です。(データの名前は、このように式の一部として使うことがあるので、半角英数字を並べたものにしておくのが無難です。スペースや句読点が入っていると、面倒なことになります。)start=c(a=12,b=1) は、未知数である a, b の初期値を与えるためのものです。初期値を c(...) で囲むのは、R 言語特有の記法です。
問題がなければ、何もメッセージは出ません。結果を fit という変数に入れたので、この中身を見てみましょう。
> fit
Nonlinear regression model
model: A ~ a * (1 - exp(-b * time))
data: test
a b
13.1366 0.4725
residual sum-of-squares: 0.0392
Number of iterations to convergence: 5
Achieved convergence tolerance: 2.178e-06
未知変数 a, b の値が算出されています。この値に基づいた予測曲線を先ほどのグラフに重ね書きしたいときは、lines(test$time, predict(fit)) と打ち込みます。
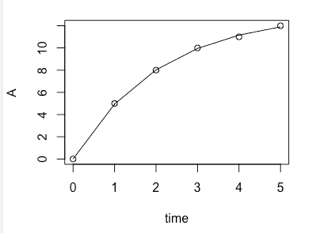
実は、ここで書いた線は、折れ線グラフです。つまり、元データの time の値ごとに予測値を計算して、その点を結んだグラフになっています。実際には、曲線近似した場合は、なめらかな予測曲線を書きたくなるでしょう。それには、(0, 1, 2, 3, 4, 5) という time の値の代わりに、もっと細かく刻んだ値が欲しいところです。こんな風にします。
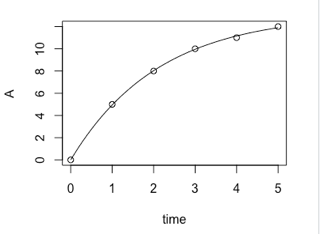
> xx <- seq(0, 5, by=0.1) # 0 から 5 まで 0.1 刻みの数値を順に発生させる
> plot(test) # 最初のプロットを書き直す
> lines(xx, predict(fit, list(time=xx)))
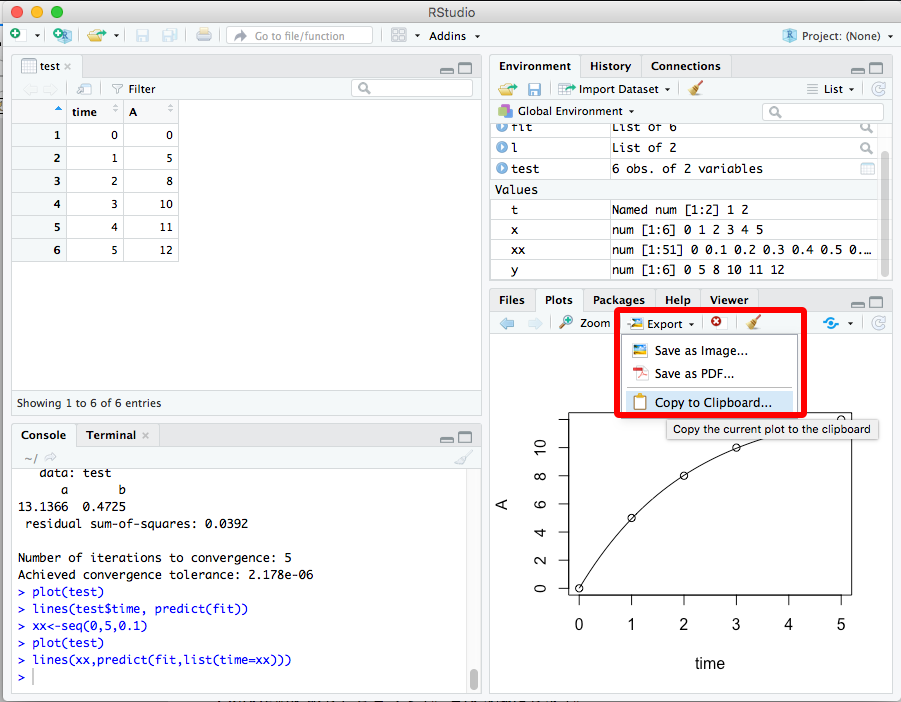
レポートなどに貼り付けるには、Copy to Clipboard... 機能を使います。
このままだと余白が多すぎるとか、縦軸の数値が 90度回転しているのは気持ち悪いとか、図としてはいろいろ改善の余地があります。そのあたりは、R の解説書などで勉強しましょう。とにかく、使い方のイメージはだいたいできました。うまく活用していきたいと思います。